Quản lý bộ nhớ vật lý trong Linux kernel (physical memory management)
Ai đã từng tìm hiểu về hệ điều hành đều biết rằng bộ nhớ vật lý được quản lý bằng cách chia nhỏ ra thành các vùng nhớ có kích thước bằng nhau, linux kernel gọi chúng là các pages, kích thước của page phụ thuộc vào kiến trúc của hệ thống, thông thường là 4KB, ví dụ ARM và X86. Thực tế thì tên gọi đúng của các vùng nhớ này là Physical frames, và mỗi frame được đại diện bởi một biến có kiểu struct page trong linux kernel.
Có lẽ mọi người đều từng nghe tới cách kernel sử dụng buddy system để cấp phát các page khi chúng ta yêu cầu thông qua các api như alloc_pages(mask, order) hay __get_free_page*, tuy nhiên liệu bạn đã từng thắc mắc rằng liệu kernel theo dõi và lựa chọn page như thế nào để trả về thông qua các api này?
Sparse memory model - cách kernel lưu physical frame trong hệ thống.
Nói nôm na thì physical memory model là cách đánh địa chỉ bộ nhớ của hệ thống, trong trường hợp đơn giản nhất, bộ nhớ vật lý của hệ thống có thể được đánh địa chỉ liên tục từ 0 đến maximum address. Tuy nhiên trong thực tế, dãy địa chỉ của bộ nhớ vật lý của thể không phải là liên tục, chẳng hạn như trong các NUMA system.
Đối với các hệ thống đơn giản, FLATMEM model có thể được sử dụng để quản lý không gian địa chỉ này. Trong FLATMEM model, một mảng global tên là mem_map sẽ được sử dụng để theo dõi toàn bộ không gian bộ nhớ vật lý, với mỗi phần tử của mảng là một struct page instance - mô tả thông tin của physical frame tương ứng. Trong model này, page tương ứng của mỗi PFN - physical frame number có thể dễ dàng được tìm ra vì chúng chỉ là linear mapping với phần tử đầu tiên của mảng mem_map sẽ có PFN là ARCH_PFN_OFFSET.
pfn_to_page(u64 x) -> {return mem_map[x - ARCH_PFN_OFFSET]}
Mặc dù vậy, model này lãng phí rất nhiều không gian bộ nhớ, vì nó tạo ra một struct page instance cho mỗi physical frame number có thể được có của Architecture, bất kể frame đó có thực sự tồn tại trong hệ thống đang chạy hay không.
Để giải quyết vấn đề này, SPARSEMEM model đã được ra: https://lwn.net/Articles/134804/
Trong model này, bộ nhớ vật lý của hệ thống được chia ra thành các phần nhỏ hơn gọi là memory section, có kích thước phụ thuộc vào architecture, và được đại diện bởi một biến kiểu struct mem_section, điều đặc biệt của model này là nó sẽ chỉ tạo ra page instance trong hệ thống nếu physical frame tương ứng thực sự tồn tại, ngoài ra đây cũng là model duy nhất trong linux cho phép memory hotplug.
Model này có một sub setting là SPARSEMEM_VMEMMAP, tuy nhiên chúng ta sẽ tạm thời bỏ qua nó.
memory section
memory section là một đơn vị quản lý bộ nhớ vật lý được đưa vào linux kernel để phục vụ cho SPARSEMEM model, đây là một đơn vị đánh dấu vùng nhớ có kích thước lớn hơn page nhưng nhỏ hơn node, với x86-64, kích thước của nó là 128MB.
struct mem_section {
unsigned long section_mem_map;
struct mem_section_usage *usage;
};Các mem_section của hệ thống được kernel lưu trữ trong một mảng hai chiều có tên là mem_section, mỗi element trong mảng này quản lý một vùng địa chỉ có kích thước 128MB (focus on x86_64),
struct mem_section mem_section[NR_SECTION_ROOTS][SECTIONS_PER_ROOT];
// put macros here for easier reference
#define SECTIONS_PER_ROOT (PAGE_SIZE/sizeof(struct mem_section))
#define NR_SECTION_ROOTS DIV_ROUND(NR_MEM_SECTIONS, SECTION_PER_ROOT)Có thể thấy rằng mỗi section root sẽ cần không gian nhớ 1 page để lưu trữ thông tin, tức là toàn bộ hệ thống của NR_SECTION_ROOTS để lưu trữ thông tin về bộ nhớ vật lý.
Với hệ thống X86_64 sử dụng 5 level page table (52 bits physical memory) thì cần tất cả 2^19 (1 << (52 - 27))sections để theo dõi thông tin bộ nhớ vật lý, tương tự thì đối với hệ thống sử dụng 4 level page table sẽ là 2^11 sections.
Truy cập pages trong SPARSEMEMORY model
Trường section_mem_map(unsigned long, nhưng thưc tế nó là một con trỏ tới một mảng 1 chiều) của struct mem_section chính là một con trỏ tới phần tử đầu tiên của một mảng có chứa PAGES_PER_SECTION phần tử, mỗi phần tử là một instance của struct page - đây chính là nơi kernel lưu trữ các page trong hệ thống.
mem_section
+-----------------------------+
|usage |
| (mem_section_usage *) |
| |
| |
+-----------------------------+ mem_map[PAGES_PER_SECTION]
|section_mem_map | ----> +------------------------+
| (unsigned long) | [0] |struct page |
| | | |
| | +------------------------+
+-----------------------------+ [1] |struct page |
| |
+------------------------+
[2] |struct page |
| |
+------------------------+
| |
. .
. .
. .
| |
+------------------------+
|struct page |
| |
+------------------------+
[PAGES_PER_SECTION - 1] |struct page |
| |
+------------------------+
Lưu ý rằng, mem_section ứng với mỗi section index sẽ luôn tồn tại trong hệ thống, tuy nhiên mảng section_mem_map chỉ được allocate nếu như section này là hợp lệ - tức là có physical frame number nằm trong section này, do đó nó tiết kiệm được rất nhiều không gian bộ nhớ trong các hệ thống mà địa chỉ vật lý là không liên tục.
Điểm trừ của model này là các hàm như __page_to_pfn và __pfn_to_page có phần phức tạp hơn, do chúng phải tìm ra section trước khi có thể tìm ra page tương ứng.
Quá trình khởi tạo sparse model trên x86_64
Qúa trình này bắt đầu tại bằng hàm sparse_init(), hàm này thường được gọi đến thống qua các lời gọi hàm trong setup_arch()
setup_arch() -> x86_init.paging.pagetable_init() -> paging_init() -> sparse_init()
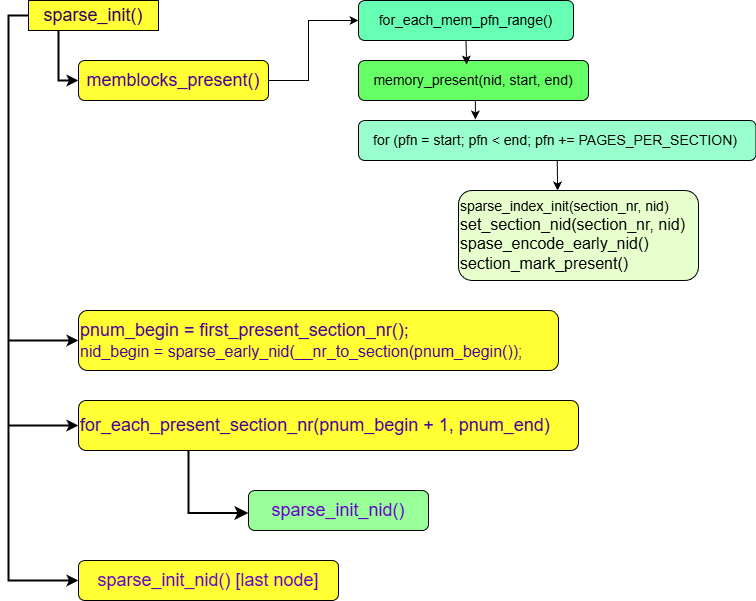
Hàm memblocks_present có nhiệm vụ đánh dấu các mem section tồn tại trong hệ thống bằng cách set bit SECTION_MARKED_PRESENT của ms->section_mem_map
Hàm sparse_init_nid(int nid, unsigned long pnum_begin, unsigned long pnum_end, unsigned long map_count) có nhiệm vụ khởi tạo sparse model cho node nid, node này chứa các mem section nằm trong khoảng từ pnum_begin đến trước pnum_end.
sparse_init_nid sẽ sử dụng các alloc api của memblock để allocate một mảng kiểu page[] gồm PAGES_PER_SECTION phần tử và encode địa chỉ của mảng này vào ms->section_mem_map.
map = __populate_section_memmap(pfn, PAGES_PER_SECTION,
nid, NULL, NULL); // allocate a page array
....
check_usemap_section_nr(nid, usage);
sparse_init_one_section(__nr_to_section(pnum), pnum, map, usage,
SECTION_IS_EARLY); // encode PFN to ms->section_mem_map
Lưu ý là ms->section_mem_map sẽ được encode như sau:
ms->section_mem_map = mem_map_addr - section_to_pfn(sec);
Trong đó mem_map_addr là địa chỉa của phần tử đầu tiên trong mảng []page, còn section_to_pfn(sec) sẽ trả về PFN của page đầu tiên trong section này.
Một số lower bit của ms->section_mem_map sẽ được sử dụng để lưu các flags
Truy cập thông tin từ Sparse model
#define __page_to_pfn(pg) \
({ const struct page *__pg = (pg); \
int __sec = page_to_section(__pg); \
(unsigned long)(__pg - __section_mem_map_addr(__nr_to_section(__sec))); \
})
#define __pfn_to_page(pfn) \
({ unsigned long __pfn = (pfn); \
struct mem_section *__sec = __pfn_to_section(__pfn); \
__section_mem_map_addr(__sec) + __pfn; \
})
Do ms->section_mem_map = start_page - start_pfn nên pg - ms->section_mem_map sẽ là pg - start_page + start_pfn = PFN của pg. section_mem_map đã chứa luôn start_pfn của section mà không cần phải tạo thêm một trường khác để lưu nó.
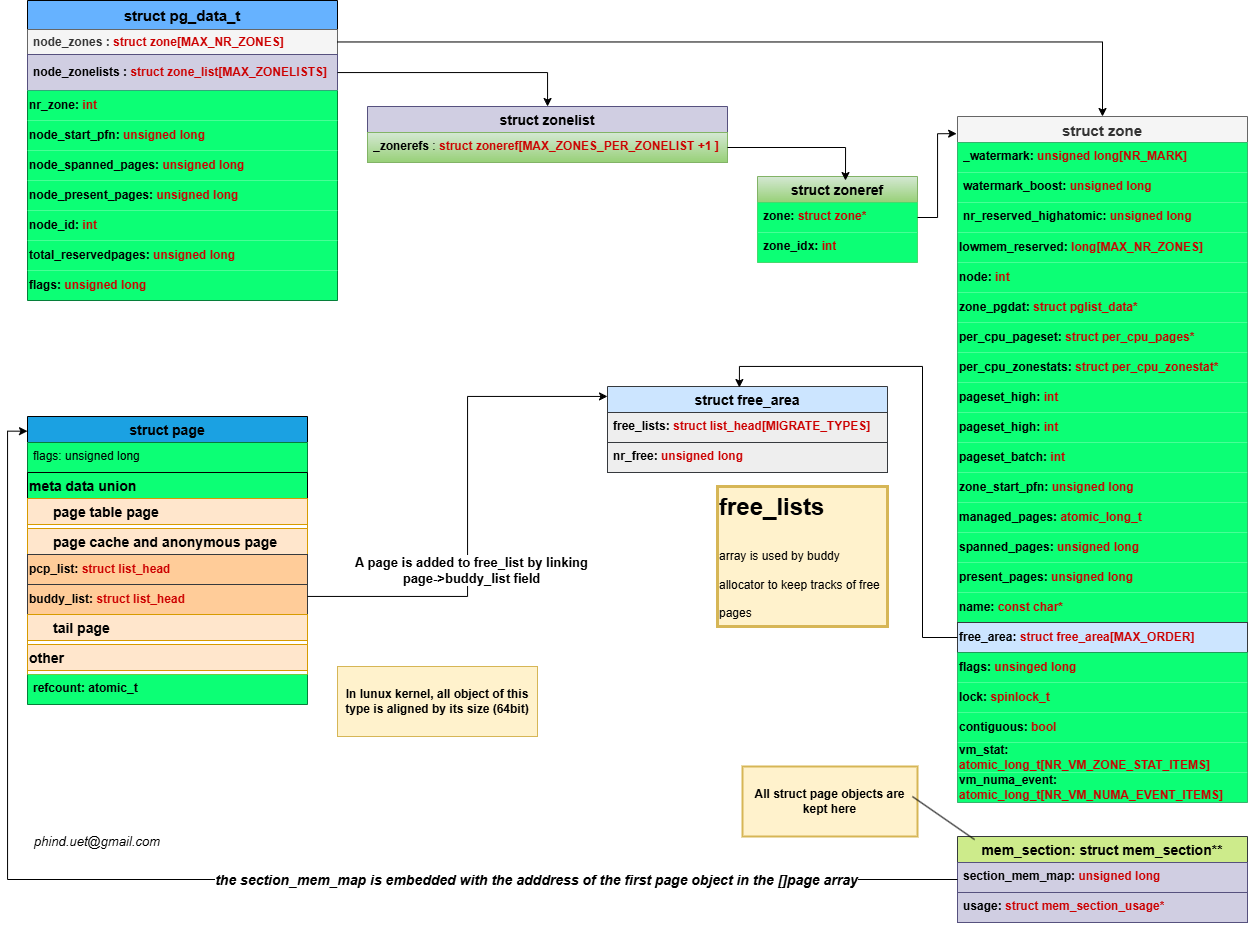
Node và zone
Trong các hệ thống hiện đại, các vùng nhớ khác nhau của bộ nhớ chính có thể mang đến tốc độ truy cập khác nhau đối với các Core khác nhau. Ví dụ như một hệ thống có nhiều CPU socket khác nhau với các memory bank được gắn trực tiếp vào các socket này, các CPU sẽ truy xuất đến các memory bank trên socket của nó nhanh hơn các memory bank được gắn vào socket của các CPU khác. Các hệ thống này được gọi là NUMA (Non-uniform memory access), thiết kế này cho phép OS có thể tăng performance của một process bằng cách schedule nó tới CPU gần với vùng nhớ chứa dữ liệu của process này (CPU-Pinning).
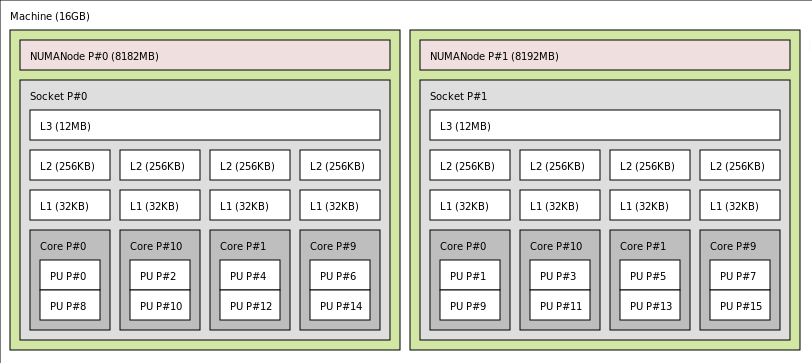
Trong linux kernel mỗi NUMA node được thể hiện bằng một object kiểu struct pglist_data alias pg_data_t. X86_64 định nghĩa một mảng tĩnh struct pglist_data *node_data[MAX_NUMNODES] __read_mostly; để lưu trữ các object này (MAX_NUMNODES tùy vào config, tối đa là 1«10 đối vỡi intel). Các NUMA node trong hệ thống sẽ được thiết lập meta data thông qua code path
start_kernel();
-->setup_arch();
--> initmem_init();
--> x86_numa_init();
Trong khi đó zone được dùng để phân chia bộ nhớ thành các khoảng địa chỉ vật lý liên tục mà các địa chỉ trong cùng một zone sẽ có cùng đặc tính riêng biệt:
- ZONE_DMA: sử dụng cho direct memory access của các legacy device (thường chỉ truy cập được 16MB đầu tiên của bộ nhớ)
- ZONE_DMA32: Tương tự zone DMA, nhưng có thể dùng cho các device có thể truy cập đến địa chỉ 4GB
- ZONE_NORMAL: Vùng nhớ thông thường
- ZONE_HIGHMEM: Cái này chỉ dùng cho các hệ 32bit cũ (intel)
- ZONE_MOVABLE: Zone ảo, không phản ánh về đặc tính địa chỉ vật lý mà phản ánh khả năng di động của page
Mỗi node metadata object (pg_data_t) chứa thông tin các zone của mỗi node trong field pg_data_t->node_zones[MAX_NR_ZONES].
Mỗi struct zone chứa một mảng các free lists cho mỗi page order size (index << 2 of pages per pageblock) trong field zone->free_area[MAX_ORDER], field này được bảo vệ bới một spinlock.
Mỗi free_area chứa một mảng các head pointer đến một linked list chứa các free page trong free_area có cùng Migrate_types : free_area->free_list[MIGRATE_TYPES].
Hiện tại, trong linux kernel có các migrate types sau:
- MIGRATE_UNMOVABLE: Những page có migrate type này không thể được di cư. Thông thường đây là các page được allocate bởi kernel mà được truy cập trực tiếp bằng indexed tới địa chỉ vật lý mà không có abstraction nào nên không thể được di chuyển.
- MIGRATE_MOVABLE: Các page này có thể được duy chuyển tùy ý, thông thường là các page thuộc về user land, được truy cập thông qua abstraction (virtual address) nên địa chỉ vật lý thực tế không quá quan trọng.
- MIGRATE_RECLAIMABLE: Slab pages, không thể di chuyển, nhưng có thể được reclaimed thông qua shirnking.
- MIGRATE_HIGHATOMIC: Một migrate type đặc biệt để reserve bộ nhớ cho atomic allocation
- MIGRATE_CMA: Sử dụng cho Continous memory allocation (CMA), các page này cũng có thể dùng cho MOVEABLE allocations.
- MIGRATE_ISOLATE: Không được động tới.
Tại sao chúng ta phải phân loại các pages vào các migrate type khác nhau? Một vấn đề nan giải của linux kernel cũng như các OS khác là memory fragmentation. Không giống như đối với disk fragmentation, chúng ta không thể dễ dàng sắp xếp lại các page để giải quyết vấn đề này được, linux kernel chọn cách phòng tránh memory fragmention là chủ yếu, việc di sửa đổi memory layout để giải quyết các phân mảnh đã xảy ra được xem như giải pháp cuối cùng
Migratype là một cố gắng nữa để giải quyết vấn đề nan giải này. Trong ngữ cảnh của buddy allocator, khi giải phóng bộ nhớ, allocator sẽ Gộp các page nhỏ hơn với buddy pages của nó để tạo thành page có order lớn hơn. Giả sử như chúng ta tìm được một vùng nhớ có dạng : [F] [A][F][F][F], thì nếu các page này là movable chúng ta có thể migrate page thứ 2([A]) để tạo thành 1 page order-2. Tuy nhiên nếu như các page MOVABLE và UNMOVABLE nằm cạnh nhau thì chúng ta không thể thực hiện được điều này. Kernel sử dụng các page blocks với kích thước là pageblock_order để gom các page có cùng MIGRATE lại với nhau. Các free_list của buddy allocator sẽ được chia nhỏ ra theo các MIGRATE_TYPE, các hàm allocations sẽ phải chỉ rõ MIGRATE mà nó muốn dùng để cấp phát bộ nhớ. MIGRATE_TYPE của 1 page có thể được lấy từ hàm get_pageblock_migratetype() Tại thời điểm khởi động, tất cả các pages đều là MIGRATE_MOVABLE, sau đó memmap_init_range() sẽ update migrate type của các page.
Các zone sẽ được thiết lập thông qua path
start_kernel();
--> mm_core_init();
--> build_all_zonelists(NULL);
--> build_all_zonelists_init(void);
--> static void build_zonelists(pg_data_t *pgdat);
--> build_zonelists_in_node_order();build_zonelists_in_node_order(pg_data_t *pgdat, int *node_order, unsigned nr_nodes);
--> build_zonerefs_node()
--> void build_thisnode_zonelists(pg_data_t *pgdat)
Mối liên hệ giữa các data struct sử dụng trong quản lý bộ nhớ vật lý.